






 |
|
Nr. 58
|
"Aufklärung ist der Ausgang des Menschen aus seiner
selbstverschuldeten Unmündigkeit."
Aus der Schulzeit kennt wohl jeder diesen Satz, der Immanuel
Kants Schrift "Was ist Aufklärung?" einleitet. Die Aufklärung
wurde spätestens mit der Französischen Revolution unumkehrbar,
d.h. vor 211 Jahren. Selbst Kant ist also mittlerweile doch reichlich grau
vom Staub der Jahrhunderte - oder vielleicht doch nicht? Ruft man besagte
Schrift von gutenberg.aol.de
ab und liest nur die erste Seite, wird man schonungslos eines anderen belehrt.
Zwar spielen Kants Ausführungen an vielen Stellen auf die vom Großen
Friedrich gewährte Meinungs- und Religionsfreiheit an und preisen
die Weisheit dieses Monarchen. Die Einleitung aber ist überall dort
und unverändert noch heute gültig, wo Menschen die Freiheit des
Geistes noch nicht erlangt oder wieder verloren haben. Oder den
Verlust gar nicht bemerken (wollen) ...
"In the future we will treat users just like computers - they are both programmable." soll Bill Gates gesagt haben. Das lassen Sie dem Mann durchgehen? Denken Sie daran, wenn Sie das nächste Mal mit der Maus auf [OK] klicken, denn das müssen Sie gar nicht, Sie können auch die Hand an der Tastatur lassen und Enter drücken. Das wäre der kleinste mögliche Protest gegen die Point-and-Click-Mentalität, auf die fast alle Windows-Anwender schon programmiert sind. Millionen denken so, wie es die Programme aus der M$-Schmiede suggerieren; verborgen bleibt allzu oft, dass man mit Kanonen auf Mücken schießt oder überflüssigen (aber Zeit und Bandbreite kostenden) Firlefanz in Kauf nimmt. Doch ist das schon Unmündigkeit oder ist es nur der pragmatische Kompromiss, Nebeneffekt der im Interesse von Effizienz und Produktivität nun einmal notwendigen Konventionen und Standards? Gab es "Sachzwänge" nicht zu allen Zeiten, und muss nicht individuelle Freiheit immer Zugeständnisse an das Allgemeinwohl machen? Dazu Kant: "Satzungen und Formeln, diese mechanischen Werkzeuge eines vernünftigen Gebrauchs oder vielmehr Mißbrauchs seiner Naturgaben, sind die Fußschellen einer immerwährenden Unmündigkeit." Satzungen und Formeln - dazu gehören Konventionen, Normen und heute auch sogenannte Standardsoftware. Aus dieser Sicht der Dinge gehen wir längst über den kleinsten möglichen Protest weit hinaus, indem allegro-Datenbanken unverändert auch auf anderen Plattformen laufen können. In naher Zukunft soll ferner der avanti-Server, der Zugriffe aus anderen Umgebungen heraus ermöglicht, weiter verbessert werden. Neue Offenheit, neue Mündigkeit für Entwickler!
"Unmündigkeit ist das Unvermögen, sich seines Verstandes ohne Leitung eines anderen zu bedienen.", lautet Kants zweiter Satz in der zitierten Schrift. Fällt es schon in diese Rubrik, wenn man, zu reformiertem Schreiben gehalten, nicht mehr ohne ein Rechtschreibprüfprogramm auszukommen meint? Das meistgenutzte (laut Testberichten nicht das beste) dieser Programme kommt - Sie ahnen woher. Unversehens wird so für immer mehr Zeitgenossen der Mann aus Redmond indirekt zu einem jener "Vormünder, die die Oberaufsicht über sie gütigst auf sich genommen haben". (Nicht viel fehlt, und jede Schreibung gilt als akzeptabel, die in WinWord durchgeht.) Das mag indessen ein bloßes Randproblem in der Übergangszeit sein; die Reformer haben das sicher so nicht gewollt, sie handelten vielmehr in tiefem Verantwortungsbewusstsein für das Kulturgut "Schriftsprache": zu wertvoll ist dieses, als dass man die Hoheit darüber einem Parlament ausliefern dürfte. Hier muss vielmehr der Volksverstand sich der umsichtigen Leitung durch die Kultusministerkonferenz anvertrauen. Zudem will letztere mitnichten "das Volk" entmündigen, ihr Dekret bindet nur Schulen und Behörden. Alle anderen sind ausdrücklich frei, sich ihres eigenen Verstandes zu bedienen. Den Zwang zu einheitlicher Schreibung, eine jener "Fußschellen", hat also de facto nicht ein sich aufklärendes Volk selber abgestreift, sondern eine Obrigkeit hat ihn zum alten Eisen geworfen. Das grenzt an friderizianische Weisheit - jeder darf nach eigener Fasson kreativ werden, Nichtbeherrschung der Orthografie kann keine Chancen mehr zunichte machen, denn es gibt "die" Orthographie nicht mehr. Und allenthalben, selbst z.B. im SPIEGEL, kann man jetzt beobachten, wie die neue Freiheit frische, früher nie gesehene Fehlerblüten treibt: notwändig, Glaß, Preis geben, Aussage kräftig, zu nichte, mit Nichten, schlechtest gekleidetste, Gefahr drohend, am schwer wiegendsten, bein halten. Man ist versucht, Schiller umkehrend, den Reformern zuzurufen: "Eure Zauber teilen wieder, was Kultur einst streng geeint".
Genug davon, diese Blätter sind kein Organ für Kulturkritik - jeder bediene sich des eigenen Verstandes zum Weiterdenken, "Sapere aude!" nach Kant, nur Mut! Die Auswirkungen der Rechtschreibreform auf unsere Kataloge, das ist ein Thema, dem wir uns in unserem Umfeld zu stellen haben, wenn es auch vom öffentlichen Problembewusstsein so gut wie ignoriert wird. Eine Untersuchung fand schon vor zwei Jahren statt, die Resultate sind auf unserem Webserver nachzulesen. Es gab in der Folge auch ein paar Verbesserungen an den Standard-Indexparametern. Nicht alle Differenzen kann man abfangen, das muss gesagt werden; insbesondere die neuen Getrenntschreibungen ("nicht linear" statt "nichtlinear" etc.) werden Ärger machen. Einer Leitung durch den künstlichen "Verstand" kann man sich nicht bedienen, man muss noch mehr mitdenken als zuvor.
In Programmiersprachen ist es mit der Orthografie noch schlimmer als in natürlichen Sprachen. Fehlfunktionen bis hin zu Abstürzen kann der kleinste Verstoss nach sich ziehen. Auch die allegro-Exportsprache ist eine Programmiersprache. Abschaffen kann man sie nicht, aber die Notwendigkeit zurückdrängen, sie benutzen zu müssen. Das wurde bereits im DOS-System versucht (in den Paketen QUEX, QUANT, PRONTO). In a99/alcarta kann man jetzt gleichfalls Listen produzieren, ohne zu parametrieren, und zwar ganz besondere Listen, sog. Views, die neue Sichten auf Ergebnismengen gewähren (ab S.2).
Sogenannte Standard-Software kommt nicht nur von der Gates-Company. Eine neue Sicht des Gesamtsystems stellen wir vor in einer "Vergleichenden Gegenüberstellung" mit Relationalen Datenbanksystemen, die weithin als Standard gelten. Dadurch wird endlich die Kommunikation mit nichtbibliothekarischen Datenbänkern erleichtert, in deren Katechismus "SQL" steht. Als diese Übersicht im Web erschien, zeigten die Reaktionen bald: das ist willkommene Aufklärung (ab S. 10).
"Warschauer Paket"
Ergebnismengen können bislang nur mit Hilfe der Kurztiteldatei der Datenbank (.STL) betrachtet werden. In der Kurzanzeige sieht man zu jedem Satz die zugehörige Kurzzeile. Zum Ordnen der Ergebnismenge können in a99/alcarta nur diejenigen Kriterien verwendet werden, die in der Kurzzeile auftreten (oder mit Alt+s die interne Satznummer).
Nicht immer ist für einen konkreten Zweck die Kurzzeile gut geeignet, weil sie immer gleich aussieht (denn es gibt nur genau eine je Satz). Manchmal bräuchte man einen Überblick mit anderen Datenelementen, manchmal auch müsste man eine andere Ordnung herstellen können. Zum Beispiel sind die Kurzlisten bei einer bolero-Datenbank nach dem Einheitstitel geordnet, manchmal ist aber eine Übersicht nach Opusnummern erwünscht oder auch nach Interpreten, Dirigenten, Aufführungsjahren, Orchestern ... nichts davon steht aber in der Kurzliste.
Man hätte also gern geschmeidige Alternativen zur Standard-Kurzanzeige, um Ergebnismengen in einer dem Zweck angemessenen Form und Reihenfolge durchsehen oder auch exportieren zu können. Denn Datenbanken können viele unterschiedliche Satztypen enthalten und es können immer neue und neuartige Ansprüche über eine Datenbank hereinbrechen, z.B. wenn man Geschäftsgänge damit unterstützt oder betreibt.
Angedacht wurde schon einmal, dass es mehr als nur eine STL-Datei geben könnte. Zwar würde dies für eine Reduzierung gähnender Leerräume auf zeitgenössischen Festplatten sorgen, dennoch aber hätte man nur eine begrenzte Zahl von letztlich auch wieder voreingestellten und wenig anpassungsfreudigen Sichtweisen, weil man dazu gute Parametrierkenntnisse braucht und schnelle Änderungen selten machbar sind, im laufenden Betrieb überhaupt nicht.
Kurzum: die Sicht (engl. view) der Dinge, sprich der Ergebnismengen, sollte flexibel einstellbar sein und wenn irgend möglich ohne großes Insiderwissen kurzfristig, am besten ad-hoc neue An- und Einsichten eröffnen. Schließlich ist die Datenbank kein Selbstzweck, sondern sie soll Früchte tragen.
Aus der Sicht des classico-Systems ist außerdem noch festzustellen:
Per CockPit können aus Ergebnismengen beliebig sortierte Listen erstellt werden (siehe Handbuch Kap. 6), doch wird dies trotz Vereinfachungen noch immer als relativ umständlich empfunden. Im Windows-System soll es mindestens soviel Flexibilität geben, aber man wünscht sich entscheidend weniger Parametrierarbeit und die Möglichkeit, die Vorgänge online durchzuführen und mit sofortiger Betrachtung der sortierten Liste, wahlweise jedoch auch mit einer Druck- oder Dateiausgabe in Listen- oder Tabellenform. Letztere könnte dann nebenbei unter Windows die "alten" CockPit-Funktionen der Listenproduktion ersetzen.
Aber wieso "Warschauer Paket"?
Um die genannten Ziele zu erreichen, ist das "View"-Konzept entwickelt worden. Weil die ersten Ideen schon vor einer Weile bei einem Arbeitsbesuch in der polnischen Hauptstadt skizziert wurden, kam für die heranreifende Sammlung von FLEXen, Parametern und Hilfedateien dieser eigenartige Codename auf.
Wir sprechen bei der fertigen Lösung nun aber im Klartext von "ViewListen":
Eine ViewListe ist eine besondere Form der Darstellung einer Ergebnismenge.
Eine ViewListe gestattet das Durchsehen, Durchsuchen
und Exportieren einer Ergebnismenge in einer sinnvollen Reihenfolge
und mit Anzeige von zweckdienlichen Feldinhalten, und zwar
bei Bedarf mit Gruppierung nach einem gewünschten
Feld und mit Summierung von Zahlen.
Sie wollen das sofort sehen? Ab Seite 6 steht, wie's geht.
Im Folgenden wird immer das englische Wort "View" statt des deutschen "Sicht" benutzt.
Unter derselben Bezeichnung gibt es etwas Ähnliches, aber grundsätzlich doch Anderes bei relationalen Datenbanken. Dort ist ein View ein zur Datenbankstruktur gehöriges Element, einzurichten vom Systemverwalter und dann permanent vorhanden, aber selten schnell realisierbar oder änderbar. Für allegro ist ein View eine temporäre Datei, erstellbar durch jeden Datenbankbenutzer, jederzeit und sofort. Die entwickelte Methodik ist einerseits sofort einsetzbar, ohne langes Vorstudium, andererseits kann man mit einschlägigen Kenntnissen, wie bei allegro üblich, für lokale Zwecke und kompliziertere Aufgaben beliebige Varianten und Verfeinerungen ausarbeiten. Das gilt für die Parameterdateien sowohl wie für die FLEXe.
Datentechnisch besteht eine ViewListe aus einer sehr einfachen Textdatei mit je einer Zeile für jeden Datensatz. Solche Dateien können leicht und schnell erstellt werden, auch außerhalb von a99/alcarta, z.B. mit PRESTO oder SRCH. Die View-Funktionen gibt es nur für a99/alcarta , nicht für die konventionellen Programme; es wurde dafür der neue FLEX-Befehl "View" eingerichtet.
Aber nicht nur Ergebnismengen können als "ViewListe"
präsentiert und genutzt werden, auch Textlisten aller Art und beliebiger
Größe: Auswahllisten für Codes oder Systematiken, Menülisten
(wobei hinter jeder Zeile ein FLEX stecken kann). Und diese Listen können
komfortabel durchsucht werden. Vielleicht wird die praktische Bedeutung
dieser Sonderfunktion nicht geringer sein als die der Ergebnismengen-Nutzung.
Einzelteile des View-Konzepts [Hintergrundwissen für Allegrologen]
Nutzung der View-Technik setzt voraus, dass man auf dem Arbeitsverzeichnis Schreibrecht hat. Wenn in der INI-Datei kein Befehl DbAux=... steht (mit dem man das Arbeitsverzeichnis setzt), wird dasjenige genommen, das in der Environment-Variablen TEMP steht. Meistens ist dies c:\windows\temp. Dort kommen die temporären Dateien zu liegen, die nach Ende einer Sitzung ohne Weiteres gelöscht werden können. Die Parameterdateien (vom Typ v-*.cpr ), die man nicht selten später erneut gebrauchen kann, werden auf das Startverzeichnis geschrieben, desgleichen Exporte, was man durch Eingriff in die FLEXe aber ändern könnte.
Eine ViewListe hat die Extension .VW. Sie besteht aus Zeilen von exakt gleicher Länge (Auffüllung am Ende mit Leerzeichen!). Ist das beim Aufruf nicht gegeben, wird das Programm selbständig eine Kopie der Datei erstellen und darin alle Zeilen an der längsten ausrichten. Jede ViewListe kann aber ihre individuelle, passende Zeilenlänge haben.
So sieht, schematisch, ein Datensatz, d.h. also eine Zeile, in einer ViewListe aus:
00001234|TEXT 13 10
Die hochgestellten, unterstrichenen Zahlen 13 und 10 sind die üblichen ASCII-Steuercodes für die Zeilentrennung. Warum die feste Länge? Diese macht es viel schneller, die Anzeige dann erscheinen zu lassen und darin zu blättern, als wenn die Zeilen variabel wären. Bei Ergebnismengen von mehreren tausend Sätzen wirkt sich dies sehr spürbar aus. ViewListen sind in aller Regel temporär, daher kann man sich diese Ineffizienz leisten. (Übrigens: Hat eine ViewListe ausnahmsweise Zeilen unterschiedlicher Länge, merkt das Programm dies beim Einlesen und korrigiert es, d.h. die Datei wird entsprechend verändert; es dauert nur etwas länger, bis sie dann erscheint! Tip: Wenn man eine ViewListe von Hand anlegt, mache man die erste Zeile mindestens so lang wie die längste Zeile, dann geht das Einlesen am schnellsten.)
Der Inhalt eines View-Satzes ist zweiteilig: eine interne Satznummer (hier 8stellig mit führenden Nullen, das ist jedoch nicht verbindlich), und ein davon durch das Zeichen '|' getrennter TEXT, eine beliebige Zeichenkette. Diese besteht normalerweise aus Elementen des Datensatzes, dessen Nummer vorn steht, und zwar genau den Elementen, die man für einen bestimmten Zweck braucht. In der Regel wird dieser Text in sinnvoller Weise sortierbar sein, wobei die zum Sortieren dienenden Elemente vorn stehen müssen.
Erfreuliche Nebenwirkung: Jede Datei xyz, die so aussieht, kann mit dem FLEX-Befehl View xyzals ViewListe angezeigt werden, egal wie man sie erstellt hat! Im Extremfall ist es eine Textdatei ohne ein '|' oder mit jeweils "abc|" am Anfang jeder Zeile, wobei 'abc' nicht mit einer Ziffer beginnt. Die ViewListe wird angezeigt im Kurzanzeige-Fenster und erlaubt dann die Auswahl einer Zeile. Beginnt die Zeile mit einer Nummer größer als Null, wird der zugehörige Satz sofort angezeigt, wenn der Leuchtbalken darauf geht. Man hat hier nebenbei eine Alternative zum FLEX-Befehl "select", denn:
Anschließend (nach Druck auf [Enter]) steht die ausgewählte Zeile dann in der "internen Variablen". D.h. die Angabe "abc", im View nicht sichtbar, kann dann auch per FLEX ausgewertet werden! Kommt kein '|' vor, ist die ganze Zeile sichtbar.
Wie könnte nun der TEXT zusammengestellt werden? Vielleicht einfach so, dass man die gewünschten Kategorienummern angibt? Das mag in einfachen Fällen reichen und wird auch über ein Formular komfortabel gelöst, siehe unten (Seite 6), aber wenn die gesamte Bandbreite der potenziellen Wünsche abgedeckt werden soll, muss man vieles bedenken:
Eine ViewListe entsteht in beiden Fällen als Export einer Ergebnismenge mit Hilfe einer View-Parameterdatei, kurz ViP genannt, mit einem Namen der Form V-XYZ.APR, die immer denselben Aufbau hat. Den Teil mit den allgemeinen Exportparametern kann man für andere Kategoriesysteme einfach kopieren. Die speziellen, auf den jeweiligen Zweck bezogenen Angaben bilden einen Block, der jeweils für eine neue Aufgabe zu bearbeiten ist. Im classico-System entsprechen diesen Dateien die Parameterdateien S-*.APR zur Erstellung einer Sortierdatei. Es kann beliebig viele solche ViPs geben.
Das Erstellen von ViP-Dateien ist Sache des Systemverwalters, der dafür aber nur relativ wenige Parametrierkenntnisse braucht (es sei denn, man hat sehr diffizile Wünsche).
Das Anwenden der ViPs ist, wie das Anwenden der Sortierdateien im classico-System, ohne Parameterkenntnisse möglich, zumal wenn die Anwendung auch noch in FLEXe eingebettet wird. Als kommentierte Vorlage benutzt man die Datei V-STAND1.APR oder V-STAND2.APR (letztere mit Gruppierung und Summierung) oder eine andere vorhandene ViP.
Hier ein Beispiel:
In der Datei V-STAND2.APR (für den Standard-View 2 ) findet man in der Mitte diesen Abschnitt:
Abschnitt für die eigentliche ViewListe:
#76 +#40 x"*1" x">1449" e"."
u e4 P'///' Avv
#nr p"o.J.///" e7 Avv
#40 e" = " u e15 F" " P": "
Avv
#20 u e40 Avv
#77 +D x"*1" x"r2" r7 F"." =vu
#vu wird dann zur Summierung benutzt
#nr p'00000000' e7 =vu
#+D Sprung zur Verarbeitung
von #uvv
Abschnitt fuer den Tabellenexport (Trennzeichen zwischen Feldern)
#-Q Benutzung aus VIEWTAB.FLX
heraus mit "download view"
#uxV +- c't|' B'|' f' |' e0
Trennstrichzeile: nicht verarbeiten
#uxV c'a|' B'|' f' |' F' ' Überschriftzeile
ausgeben
#76 +E x"*1" e4
#nr p"o.J." e4
#-E
#t9 Zwischenteil 9 als Trennzeichen
(Definition in view1.apt)
#40 e" = "
#t9
#20
#t9
#77
#uxV c's|' B'|' f' |' F' ' Summenzeile
(erscheint dann rechts)
anschließend kommt das
standardisierte Endstück: view2.apt
Will man für die ViewListe eine Spaltenanordnung, kann man das jeweils mit den Befehlen en sn erreichen, also z.B. e20 s20um die Länge des Abschnitts auf 20 Zeichen zu begrenzen und mit Leerzeichen aufzufüllen.
Für die Differenzierung der Anzeige des Views gibt es zwei Möglichkeiten. Dabei wird nach dem Sortieren die Parameterdatei VIEWGRUP.APR benutzt, die man unverändert auch für andere Kategoriesysteme einsetzen kann.
Daraus macht das Programm SRCH mit der Parameterdatei VIEWGRUP.APR eine übersichtliche ViewListe. Die Funktion der Zeichen : und _ ist nicht im Programm "verdrahtet", sondern nur in VIEWGRUP.APR. Wer parametrieren kann, darf sich auch ganz andere Dinge ausdenken, um die ViewListe zu erstellen.
Folgende Funktionen braucht man für den Umgang mit Views:
Aber noch mehr: die schlichte Struktur der ViewListen erlaubt es sogar, Auswahllisten beliebiger Art in derselben Form zu erstellen, die dann mit dem Befehl View präsentiert werden können. Zeilen, die nicht mit einem Satz verbunden sind, sollten am Anfang die Angabe "0|" haben oder aber das Zeichen '|' nicht enthalten. Die ausgewählte Zeile geht dann in die interne Variable über und kann beliebig weiter verwertet werden. Im FLEX sieht das so aus:
ViewListe anzeigen:
View dateiname (Achtung:View
mit großem V, sonst keine Anzeige, sondern nur Dateiöffnung)
Es wurde [Esc] gedrückt:
if cancel jump xxx
Es wurde eine Zeile ausgewählt
(mit Enter oder [OK]): in #uaw kopieren
ins #uaw
...
In #uaw hat man anschließend die ausgewählte Zeile aus der ViewList und kann damit beliebig umgehen.
Tip: Um eine bestimmte ViewListe, die man vorher produziert hat, erneut zu sehen, kann man sie auch manuell aufrufen: man gibt im Schreibfeld ein
x View dateiname
Verbesserungen von ASORT
Das DOS-Sortierprogramm ASORT.EXE wurde so verbessert, dass es die Aufgaben des View-Konzepts wahrnehmen kann, wenn auf DOS-Ebene eine ViewListe hergestellt werden soll:
Option -u3
Wie erstellt und nutzt man eine ViewListe?
Dazu gibt es mehrere Möglichkeiten, die mit fertigen Parametern und FLEXen unterstützt werden. Weitere Methoden und Varianten lassen sich entwickeln, wenn man die Bausteine erst einmal beherrscht (siehe oben).
Zuerst braucht man eine Ergebnismenge. Wie man eine macht, wissen Sie. Was darin ist und wie groß sie ist, spielt keine Rolle. Der Name steht unten auf der langen Schaltfläche, wie immer. Was macht man, um eine "Neue Sicht" dieser Daten zu erhalten?
Geben Sie im Schreibfeld ein: h
view , dann erscheint in der Anzeige dieses Menü:
|
|
||
| ViewListen
erstellen
Mit Standard-ViP 1
Mit anderer ViP
Neue ViP anlegen
Mit Parametern
|
ViewListen benutzen
Aktuelle ViewListe = .... neu anzeigen (Strg+o) exportieren als Tabelle ausgeben
Vorhandene ViewListen
HILFE..HILFE..HILFE
|
Für schnelle ad-hoc-Listen
ist der Punkt Neue ViP anlegen
am wichtigsten.
Mit einem Doppelklick auf
|
Eine ViP ist eine View-Parameterdatei, also eine Vorschrift zum Erstellen der ViewListe.
Tip: Geben Sie h view.rtf ein, dann sieht man auch die zu den Menüpunkten gehörenden FLEXe.
Das Menü hat links die Funktionen zum Erstellen neuer ViewListen, rechts die zur Benutzung vorhandener ViewListen.
Der Reihe nach:
ViewListen erstellen
Mit Standard-ViPs (Ein Doppelklick genügt und alles läuft automatisch ab)
Für Views, die immer wieder gebraucht werden, kann man ein- für alle mal einige durchdachte Parameterdateien anlegen und dann Kopien des FLEX view1.flx oder view2.flx nutzen, um jeweils die aktuelle Ergebnismenge damit zu betrachten. Nur den Namen der eigenen Parameterdatei muss man darin einsetzen.
Die Parameterdateien v-stand1.apr und v-stand2.apr kann man als Vorlage oder Strickmuster für eigene ViPs verwenden. Die Stellen sind markiert und kommentiert, wo man modifizieren kann.
Den einschlägigen Parameterdateien sollte man Namen der Form V-*.cPR geben.
Wer die Exportsprache beherrscht, hat hier alle gewohnten Gestaltungsmöglichkeiten.
(dahinter steckt der Aufruf: X viewform.flx )
Das Formular sieht so aus: (F1 erklärt, was zu beachten ist)
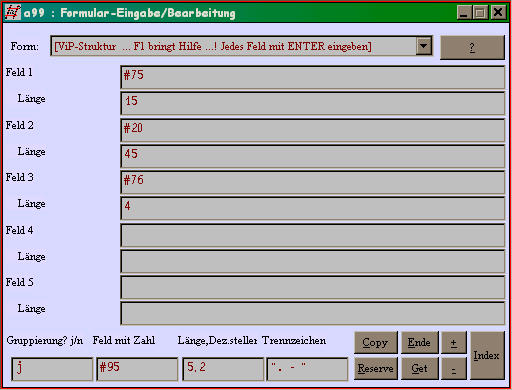 |
Hier wurde eingegeben, dass #75 (Verlag) das erste Feld sein soll,
begrenzt auf 15 Zeichen. Nach diesem Feld wird also sortiert und auch gruppiert
(unter "Gruppierung" ist j eingetragen).
Zusätzlich werden #20 (Titel) und #76 (Jahr) ausgegeben. Das Feld #95 enthält einen Geldbetrag und soll mit 5 Stellen und 2 Nachkommastellen ausgegeben werden. Es wird dann summiert, sowohl nach Gruppen als auch insgesamt. F1 bringt Hilfe!
|
Dieses Formular ist in der Datei view2.frm definiert. Die Eingaben kommen in Variablen #uvA - #uvZ und werden vom FLEX viewform.flx dann zu einer Parameterdatei verarbeitet. Diese wird benutzt, um die Ergebnismenge in eine ViewListe zu verwandeln. Wer jedoch Parametrierkenntnisse hat, kann in den Eingabezeilen "Feld 1" bis "Feld mit Zahl" auch Manipulationsbefehle mit unterbringen, z.B. #20 e" : ", damit vom Feld #20 (Sachtitel) der Zusatz abgeschnitten wird.
Neue ViP anlegen: Mit Parametern(fürAllegrologen , man braucht hierfür Parametrierkenntnisse)
(Start: x var "Start"\ins #uYa\var "X viewpara.flx"\ins #uZa\h viewpara )
Der dann erscheinende Hilfetext (Datei VIEWPARA.RTF) sieht so aus:
Wählen Sie die Kategorien, die in Ihrer ViewListe erscheinen sollen
*** Zeilen für die ViewListe
(alles in Variable #uvv kopieren!)
#40 e20 =vv
#20 U e40 p": " Avv Gruppierung
gewuenscht
#76 e5 p" (" P")" Avv
#77 x"*1" e"." p"_" Avv Summierung
gewuenscht
*** Ende ViewZeilen
#+D
Zeilen für die Tabellen-Ausgabe:
(#uxV ist die ViewZeile)
#-Q
#uxV +- c'0t|' B'|' f' |' e0
#uxV c'0a|' B'|' f' |' F' '
*** Tabellenkategorien
#20
#t9
#40
#t9
#76
#t9
#77
*** Ende Tab.Kateg.
#uxV c's|' B'|' f' |' F' '
Aber nehmen Sie die Beispielzeilen zwischen *** ... *** weg, denn jede Zeile wird verarbeitet, die mit '#' beginnt. Günstig ist, wenn die Gesamtlänge nicht größer als 80 Zeichen ist.
1. Ist Gruppierung gewünscht; dann ":" zwischen dem ersten und zweiten Feld (s.o. #20)
2. Ist Summierung gewünscht: "_" vor dem letzten Element, das dann als Zahl interpretiert wird (s.o. #77).
Die Kategoriezeilen, die man hier eingibt (mit '#' beginnend), werden anschließend als Mittelteil der ViP verwendet.
Wenn man auf Start doppelklickt, wird VIEWPARA.FLX gestartet und der Text im Anzeigefeld verarbeitet.
(Den Befehl X viewpara kann man auch mit der Hand im Schreibfeld eingeben, um dies auszulösen.)
Tip: will man die in der aktuellen Sitzung zuletzt betrachtete ViewListe erneut sehen: im Schreibfeld eingeben
x view again
Die neu entstehenden ViewListen haben bei diesen Prozeduren immer den Namen VVV.VW. Anschließend hat man die Möglichkeit, ihr einen anderen Namen zu geben und damit für eine längere Aufbewahrung zu sorgen.
Und jetzt zu den Funktionen auf der rechten Seite des Menüs:
ViewListen benutzen
Aktuelle ViewListe = liste
neu anzeigen
Hinweis: Es versteht sich von selbst, dass eine ViewListe, einmal erstellt, eine statische, von der Datenbank losgelöste Textdatei ist und daher nach kurzer Frist veraltet sein kann (sie hat keinerlei funktionale Verbindung mit der Datenbank). Ist die ViP noch vorhanden, kann man eine ViewListe aber jederzeit schnell erneuern.
Hat man gerade einen View erstellt, kann man mit dem neuen FLEX-Befehl download view die zum View gehörigen Datensätze in der durch den View gegebenen Reihenfolge exportieren. Benutzt dazu werden die aktuell eingestellten Exportparameter. Mit dem xport-Befehl kann man natürlich vorher die Ausgabedatei und/oder die Exportparameter auch anders einstellen.
Die mit 'X' markierten Zeilen werden nicht exportiert.
Ansonsten wird jede Zeile der ViewListe verarbeitet, auch diejenigen, die
keine Satznummer haben: In den Exportparametern hat man immer die aktuelle
View-Zeile in der Variablen #uxV
und kann diese darauf prüfen, ob sie mit einer Zahl beginnt, z.B.
mit den Zeilen (siehe auch Kommentar in v-stand2.apr)
#uxV +A x">0" e0
... hier die Befehle für den Fall, dass kein Datensatz vorliegt, sondern z.B. eine Überschrifts- oder Summenzeile
#+#
#-A hier geht's weiter, wenn ein Datensatz vorliegt
Ist eine ViewListe xyz.vw vorhanden, egal wie und wann sie erzeugt wurde, kann man jederzeit in einem FLEX schreiben:
view xyz.vw
down view
um den Export auszulösen.
Mit X View xyz.vw kann man die ViewListe wieder betrachten, wenn man "view" schreibt, also klein, wird nur die Datei geöffnet.
View-Erstellung in eigene FLEXe einbauen
In den FLEXen view1.flx und view2.flx sieht man, wie es gemacht wird. Diese Dateien sind ausführlich kommentiert, damit man sieht, wo eingegriffen werden kann. FLEXologen können diese Grundmodelle beliebig ausbauen.
Neue FLEX-Befehle
Neu ist: ein FLEX-Befehl kann direkt ins Schreibfeld eingegeben werden: x Befehl(sfolge) oder X flexdateiname .
Nur wenige Befehle wurden erweitert bzw. neu geschaffen, einige davon speziell für die View-Technik:
set c0/c1
|
|
|
| ... Aufbau der Ergebnismenge, dann ersten Satz laden: | ... Aufbau der Ergebnismenge, dann letzten Satz laden: |
| first | last |
| :schleife | :schleife |
| ... Befehle zur Bearbeitung des Datensatzes | ... Befehle zur Bearbeitung des Datensatzes |
| next | prev |
| if ok jump schleife | if ok jump schleife |
| ... hier geht's weiter, nachdem letzter Satz verarbeitet | ... hier geht's weiter, nachdem erster Satz verarbeitet |
FLEXe für wichtige Funktionen
Volltextsuche
Geben Sie im Schreibfeld ein: X fts . Dann wird fts.flx aktiviert. Dieser FLEX startet das DOS-Volltextsuchprogramm SRCH.EXE. Die Ergebnisse allerdings werden hinterher als a99-Ergebnismenge präsentiert und lassen sich dann genauso sortieren und exportieren. Man muss natürlich bedenken, dass eine Volltextsuche bei großen Datenmengen erheblich länger dauert als ein Registerzugriff, aber wenn für eine Auswertung nach Feldinhalten gesucht werden muss, die nicht indexiert sind, gibt es oft keinen anderen Weg. Für Allegrologen: SRCH benutzt zum Exportieren die Parameter fts.apr. Diese geben nichts anderes aus als die interne Satznummer eines jeden gefundenen Datensatzes. Korrekt funktioniert das nur mit einem SRCH.EXE ab 1.9.2000, ältere haben ein Problem in Fällen, wo es mehrere Datenbankdateien gibt (Typ .cLD).
Registerabschnitte mit Schwellenwerten
Mit dem CockPit konnte man seit langem über "Funktionen / QRIX" Abschnitte aus Registern in Dateien kopieren lassen, und zwar mit der Möglichkeit, nur Einträge mit einer gewissen Mindestzahl von Treffern (sog. "Schwellenwert") auszugeben. Dasselbe geht mit dem FLEX qrix.flx. Geben Sie also im Schreibfeld ein: X qrix, dann werden einige Fragen gestellt und die gewünschte Liste erscheint danach im Anzeigefeld. Von dort kann man sie mit Cut-and-Paste, wie immer, in andere Programme übernehmen oder aber per Menü "Datei | Anzeige speichern als ..." direkt in eine Datei kopieren.
allegro und RDBMS : Vergleichende Gegenüberstellung
Für den vorliegenden Text ist Dank zu sagen an Thomas Berger (Bonn), Mathias Manecke (DB Leipzig) und Dr. Annemarie Tews (UB Leipzig) für Beiträge und Diskussionen.
Relationale Datenbank-Management-Systeme (RDBMS) und allegro, das sind recht unterschiedliche Gebilde, die man im Grunde nicht leicht vergleichen kann. Vor allem waren die Entwicklungsziele nicht dieselben. RDBMS wurden primär (doch nicht ausschließlich) entwickelt mit Blick auf solche Anwendungen, die Berechnungen und Auswertungen erfordern, also im weitesten Sinne Faktensammlungen sowie Geschäfts- und Verwaltungsanwendungen. allegro dagegen zielte von vornherein (aber auch nicht ausschließlich) auf strukturierte Textdaten; dazu gehören als Spezialfall bibliothekarische Katalogdaten.
Als eine dritte Kategorie würde man vielleicht die sog. Suchmaschinen betrachten wollen, die aber nur für das Retrieval in Sammlungen von schwach strukturierten Texten geschaffen wurden, nicht für die Verwaltung dieser Texte. Daher kann man sie nicht als Datenbanksysteme bezeichnen, und nur um solche geht es hier.
Die nachfolgende Übersicht versucht, für Vertreter beider Umgebungen verständlich zu sein, stellt hauptsächlich strukturelle Aspekte gegenüber und beschränkt sich auch in dieser Hinsicht auf wenige, für Bibliothekszwecke wichtige Punkte. Für eine Einschätzung in konkreten Zusammenhängen wird man meistens noch weitere Kriterien berücksichtigen müssen, bis hin zu den Kosten, die hier außen vor bleiben. (Bibliotheken sind auf's Ganze gesehen, und kommerziell betrachtet, nur eine Nische, das darf man nicht verkennen.)
Vor Jahren hat einmal die DFG in ihren Förderrichtlinien empfohlen, Standard-Datenbanksysteme statt proprietärer (firmeneigener) Lösungen zu bevorzugen. De facto hieß das, man solle ein RDBMS einsetzen, denn andere umfangreichere und durchgesetzte Standards gab es und gibt es noch immer nicht, etwa für sog. "objektorienterte" Datenbanken. Die DFG-Empfehlung entsprang nicht einer Erkenntnis, dass solche Datenbanken die bestgeeigneten für bibliothekarische Zwecke seien - und bis heute hat sich das weder theoretisch noch praktisch schlüssig erwiesen. Die Empfehlung entsprang vielmehr der Hoffnung, dadurch zu herstellerunabhängigen Anwendungen kommen zu können. Idealerweise, so die Vorstellung, sollte man die Hardware und das Datenbanksystem wechseln können, ohne viel Aufwand in die Anpassung der Anwendungssoftware stecken zu müssen. Diese Hoffnung hat sich allerdings noch nirgends überzeugend erfüllt, die Abhängigkeit der Anwendungssoftware von den spezifischen Besonderheiten einer Datenbankgrundlage ist denn doch immer recht groß, auch wenn überall "SQL" draufsteht. Ist der Standard also nur vermeintlich ein solcher, oder jedenfalls ein zu schwacher?
Das Entity-Relationship-Modell, die Grundlage der
RDBMS-Theorie und -Praxis, ist ein mathematisch fundiertes Konstrukt. Es
sachgerecht anzuwenden ist eine anspruchsvolle Aufgabe. Dazu gehört
die Erstellung einer sog. "normalisierten" Tabellenstruktur. Dass RDBMS
so häufig eingesetzt werden, ohne auf ein schlüssiges,
gründlich durchdachtes, theoretisch sauberes ER-Modell aufzusetzen,
ist nicht dem relationalen Konzept, sondern den Entwicklern anzulasten.
Zu fragen bliebe also, ob sich bibliothekarische Sachverhalte in einem
ER-Modell wirklich elegant und effizient abbilden lassen. Diese sehr komplexe
Aufgabe ist wohl noch immer nicht umfassend und allgemeingültig gelöst.
Noch jeder, der es versuchte, musste feststellen, dass auf diesem Gebiet
viel mehr Teufel in viel mehr Details stecken als man gedacht hätte
und infolgedessen viel mehr Zeit zur Umsetzung gebraucht wird als man angesetzt
hatte, unerwartet viele Tabellen notwendig sind, die Anwendungsprogramme
also unerwartet groß und komplex werden. Erschwerend kommt hinzu:
ein theoretisch stimmiges Modell allein reicht nicht aus. Es kann leicht
passieren, dass ein Modell mit einigen hundert oder ein paar tausend Datensätzen
gut funktioniert, dann aber bei weiterem Anwachsen "in die Knie geht".
Es gibt manche Dinge, über die man bei kleineren Datenmengen gar nicht
nachdenken muss, die mit Millionen Daten aber auch auf stärkster Hardware
nicht mehr zufriedenstellend schnell funktionieren (z.B. "views" und vor
allem "joins"). Solche Effekte, die meistens zu unbequemen Kompromissen
zwingen, sind bei allegro, so darf man aus Erfahrung sagen, weniger
gravierend.
| Relationale Datenbanken | allegro
(Unterstrichen-kursive
Wörter verweisen auf das
Glossar der allegro-Begriffe) |
|
Struktur der Daten |
|
| Zentrales Konzept
der relationalen Welt ist das Entity-Relationship-Modell (ER-Modell).
Es geht davon aus, dass sich die in der Datenbank abzubildenden Sachverhalte
in Eigenschaftsgruppen (Entitäten) gliedern lassen, wobei jede Ausprägung
einer jeden Entität mit jeder anderen Ausprägung dieser oder
einer anderen Entität in Beziehung (Relation) stehen kann (d.h. jeder
Datensatz mit jedem anderen verknüpft sein kann). Physisch ist
dieses Modell in RDBMS in Tabellenform realisiert. Jede Tabelle
repräsentiert eine Entität, jede Zeile (auch "Tupel" genannt)
eine Ausprägung der Entität, jede Spalte eine Eigenschaft.
Wichtigste Aufgabe bei der Entwicklung einer relationalen Datenbank- Applikation ist also die Umsetzung des abzubildenden Sachverhaltes in ein ER-Modell (Normalisierung nach Codd), um aus diesem die Tabellenstruktur zu entwickeln. (Ist das nicht sinnvoll möglich, so ist das RDBMS von vornherein nicht das geeignete Werkzeug!) |
Logisch gesehen
entspricht einer Entität in allegro einem Satztyp.
Tabellen als solche gibt es nicht. In einer Datenbank-Datei können
Sätze aller Typen zugleich ohne strukturelle Zuordnung vorkommen.
Ein Datensatz ist ein zusammenhängender, durch Steuerzeichen strukturierter
Text. Wodurch der Satztyp bestimmt wird und welche Funktionen und Zusammenhänge
er hat, ist Sache der Parametrierung,
nicht der Dateistruktur.
Relationen können im Prinzip genau so wie bei einem RDBMS durch Bezugnahme auf den Primärschlüssel eines anderen Datensatzes gebildet werden. Eine automatische Integritätsüberwachung für die Datensätze gibt es nicht. Die Primärschlüssel werden durch geeignete Index-Parametrierung gebildet. Über programmierte Validierung lassen sich auch Elemente der Integritätsüberwachung (z.B. Verhinderung von Doppeleinträgen, Löschverweigerung für verknüpfte Sätze) in eine Anwendung einbauen. |
| Eine Tabelle
hat keine bestimmte Ordnung. Selektierte Teilmengen können aber per
SQL
nach jedem Attribut (Tabellenspalte) sowie nach Kombinationen von Attributen
geordnet werden.
Ein Index dient nicht der geordneten Sicht auf die Daten, sondern der beschleunigten Selektion bei größeren Tabellen. Der Index selbst wird nicht sichtbar. Will man das erreichen, muss man eine eigene Tabelle dafür machen. Neben realen kann es auch virtuelle Tabellen geben, sog. "Views". Die Software zeigt dann genau diejenigen Dinge, die für eine Funktion oder von einem Nutzer gebraucht werden, ohne dass diese Sicht als eigene Tabelle existiert. |
Eine Datenbank-Datei hat keine bestimmte Ordnung. Geordneter Überblick wird durch Indexieren ermöglicht (s.u.), wobei die Register durchgeblättert und zur Bildung von Ergebnismengen benutzt werden können. Ergebnismengen können nach mehreren Kriterien auf- und abwärts sortiert angezeigt werden. Ein eigenes Sortierprogramm kann Ordnungen herstellen (offline, für Reports und Listen), die sich nicht unmittelbar aus Feldinhalten oder aus den Registern ergeben. Die Indexierung ist das zentrale Element zur Präsentation der Daten in geordneter Form. Daneben können Ergebnismengen nach Elementen der Kurzanzeige, aber auch nach jedem Feldinhalt geordnet werden ("View"-Technik). |
| Jede Zeile einer Tabelle kann man als Datensatz ansehen, jeder Datensatz hat genau soviele Felder ('Attribute') wie die Tabelle Spalten hat, wobei einzelne leer sein können. Auch ein leeres Feld braucht jedoch Platz. (Wieviel, hängt von der internen Architektur ab. Manche füllen die Spalten mit Leerzeichen auf.) Durch Vermeidung von Redundanz (Normalisierung!) lässt sich andererseits Platz sparen. | Jeder Datensatz
enthält nur die jeweils belegten Felder.
Ein leeres Feld tritt im Datensatz gar nicht in Erscheinung, belegt also Null Byte. Es gibt Kategoriesysteme mit über 1000 Feldern (z.B. Pica: über 1.400), von denen dann viele nur selten belegt sind, da macht das denn doch etwas aus. |
| Die Struktur
der Datensätze (der Tabellenzeilen) ergibt sich sozusagen aus
der Kopfzeile der Tabelle, in der steht, was die einzelnen Spalten bedeuten
und was für Eigenschaften sie haben.
Moderne Systeme speichern die "Kopfzeilen" aber in besonderen Tabellen der Datenbank. Im Datenfeld selbst, das ist ein Unterschied zu allegro, steht kein Feldname oder Kategorienummer, sondern nur die Position bestimmt die Bedeutung des Elementes. Jede Tabellenspalte hat einen Namen (das könnte auch z.B. eine MAB-Kategorienummer sein)und wird in Abfragen und Programmen immer über diesen Namen (zusammen mit dem Namen der Tabelle) angesprochen. In SQL dient der Befehl CREATE zur Definition von Tabellen, Views und Indizes. |
Eine Konfigurationsdatei
(CFG) legt fest, welche Felder es in einer Datenbank geben darf. Dazu dient
die "Kategorieliste", die jedem logischen Datenfeld eine Nummer (engl.
tag)
zuordnet und seine Eigenschaften definiert. Die Reihenfolge dieser Nummern
hat keine funktionale Bedeutung, die Nummern müssen nicht fortlaufend
sein. Man muss sich entscheiden, ob es 2-, 3- oder 4-stellige
tags
sein sollen; nur die erste Stelle muss eine Ziffer sein. In den Parameterdateien
und in der FLEX- Makrosprache werden diese Nummern (und nicht die Feldnamen)
benutzt, um Felder anzusprechen. Es gibt Kategoriesysteme mit über
1500 Kategorien (wobei aber viele Wiederholungsfelder mitgezählt sind).
Die Konfiguration legt nicht fest, ob und wie die Felder indexiert oder angezeigt werden. Das ist die Aufgabe von Parameterdateien. |
| Jedes Feld hat einen Typ (numerisch, Datum, Text, u.a.), Textfelder haben jeweils eine festgelegte maximale Länge. Vorteil: die typspezifischen Eigenschaften können für Selektion und Integritätsüberwachung ausgenutzt werden. (Soundex-Suche bei Text, Größer-, Kleiner-Vergleich bei Datum, not nul und unique bei Primärschlüssel ...) | Jedes Feld enthält Text (automatisch bis zu 3000 Zeichen je Feld), jedoch kann jedes Feld auch zum Rechnen verwendet werden. (Neben einer Zahl kann das Feld dann trotzdem noch beliebige andere Angaben enthalten.) Bei der Eingabe können programmierbare Validierungen den Inhalt hinsichtlich gewünschter Eigenschaften abtesten und ggfls. Fehlermeldungen produzieren. |
| Felder sind
nicht
wiederholbar - das würde den Grundsätzen der Theorie widersprechen.
Sollen z.B. 5 Schlagwörter eingebbar sein, muss man dafür 5 separate
Tabellenspalten einrichten.
Soll ein Feld frei wiederholbar sein (Paralleltitel, Mitarbeiter) so ist der "saubere" Weg, es in eine eigene Tabelle auszulagern. Dies spart Speicherplatz und das Feld ist dann auch wirklich "frei" wiederholbar, nicht nur zwei oder sieben oder fünfzigmal. Falls solche Angaben allerdings eine Reihenfolge haben (1. Verfasser vor 2.), oder qualifiziert sind (Personen als Verfasser, Herausgeber oder Mitarbeiter) oder beides (Herausgeber vor 1. Mitarbeiter vor 2. Mitarbeiter), müssen in dieser zusätzlichen Tabelle zusätzliche Spalten zum Erhalt der Reihenfolge und Funktionsbezeichnungen eingefügt werden. Für die Anzeige eines Datensatzes müssen diese über Tabellen verstreuten Angaben zusammengesetzt und dem Anwender präsentiert werden. Nach einer Veränderung müssen die Angaben wieder auf alle betroffenen Tabellen verteilt werden. Der Datensatz existiert dann nur als logische Einheit, seine Teile sind verstreut. Eine halbwegs funktionsreiche bibliothekarische Anwendung kommt schnell auf Dutzende bis Hunderte von verschiedenen Tabellen und Hilfstabellen, für die dann Suchanfragen und Views programmiert werden müssen. |
Jedes Feld ist
beliebig
wiederholbar, falls man dies nicht in der CFG bewusst unterbindet.
In den meisten allegro-Anwendungen sind mehrfach auftretende Angaben in sogenannten Wiederholkategorien abgelegt: Hinter der Kategorienummer wird ein Folgezeichen "hochgezählt": 2,3,4,..., A,B,C, ..., a,b,c, ... Wenn es sein muss, kann man auf diese Art auf eine etwa 200fache Wiederholung kommen, die Reihenfolge bleibt dabei erhalten (sie wird durch die Ordnung der Folgezeichen bestimmt). Die Funktion z.B. von Personen kann je nach Anwendung auch an Kategorienummern gebunden sein (alle Herausgeber kommen dann vor allen Mitarbeitern), in anderen ist die Funktionsbezeichnung oder ein Kürzel dafür in den Daten selbst enthalten, angehängt oder in einem Teilfeld. Die Reihenfolge ist dann stets die der Eingabe, dafür ist man freier in der Vergabe von Funktionsbezeichnungen. Hat man hier einen undurchdachten Entwurf gemacht, kann das nachträgliche Ändern schwierig werden. Ein allegro-Datensatz kann nicht mehr als 500 Indexeinträge erzeugen und darf auch nicht größer als 20.000 Byte sein. Für einen Datensatz 200 Schlagworte und 200 beteiligte Personen (soll schon vorgekommen sein) und diverse Stichworte aus Freitextbeschreibungen und Dutzende von Parallelsignaturen, die alle recherchierbar sein sollen, bringen das System an oder über seine Grenzen. |
| Soll ein neues
Feld eingeführt oder die maximale Länge eines Textfeldes
vergrößert werden, muss man u.U. die gesamte Tabelle reorganisieren,
bei neueren Systemen nicht unbedingt.
Die eigentliche Arbeit bei der Einführung neuer Felder ist aber die Festlegung der damit verbundenen Funktionen. Das neue Attribut hat ja einen Zweck; dieser muss in veränderten Anzeigemasken, Suchfunktionen, Ausgaberegeln usw. umgesetzt werden. Der Aufwand für die Reorganisation der Tabelle ist in Bezug auf den Gesamtaufwand zu vernachlässigen. |
Das Einführen eines neuen Feldes geschieht durch eine Eintragung in der Kategorieliste der CFG-Datei. Von da an kann jeder Datensatz, auch jeder schon vorhandenene, dieses Feld zusätzlich erhalten, ohne dass dafür eine Datei reorganisiert werden muss. Soll das neue Feld indexiert und angezeigt werden, muss man das in die zuständigen Parameterdateien einbauen. Für die Erfassung ist das neue Feld in ein Formular oder die "Abfrageliste" einzubauen, evtl. ist eine programmierte Validierung zu parametrieren (für die Eingabeüberprüfung). |
| Felder ('Attribute') dürfen in sich strukturiert sein, jedoch wird so etwas von der Theorie und z.B. von SQL nicht unterstützt (denn Attribute sollen "atomar" sein, unteilbar also). Man müsste dafür eigene Anwendungsprogramme schreiben. Z.B. könnte man 5 Schlagwörter auch in eine Tabellenspalte hintereinander schreiben (vorausgesetzt, man hat die maximale Länge hoch genug eingestellt), aber mit SQL kann man dann nicht die Schlagwörter einzeln indexieren. Es können (redundante) zusätzliche Tabellen dafür angelegt werden, um das Suchen zu unterstützen. | Felder können
in sich beliebig strukturiert sein, normalerweise werden die Teilfelder
durch Steuerzeichen wie $a, $b usw. identifiziert (typisch für MARC-Formate),
doch es reicht auch eine konsistente Interpunktion.
Die Parametrierung bietet viele Möglichkeiten für den Umgang mit Teilfeldern und anders strukturierten Feldinhalten, ebenso die Verfahren der Eingabe und Bearbeitung. Attribute sind also keineswegs unteilbar sondern lassen sich in jeder sinnvollen Weise zerlegen. Insbesondere können Teilfelder individuell indexiert werden. |
| In moderneren
Datenbanken kann man oft "Objekte", also
Textdokumente, PDF-Dateien, Video- und Soundclips, Graphiken, komplexe Tabellenkalkulationen einbeziehen und anzeigen, abspielen oder bearbeiten. Dies ist vergleichbar mit "Plugins" in Internet- Browsern, die im Browserfenster bzw. sogar nur Ausschnitten davon agieren. |
Die Organisation solcher Objekte ist dem Anwender selbst überlassen. In geeigneten Kategorien des Datenformats können allerdings Links auf diese Objekte hinterlegt werden, über sogenannte "Flips" unterstützt allegro dann den Aufruf einer Anwendung für die Anzeige etc. der Objekte. Dies ist vergleichbar mit den Helper-Applikationen in Internet-Browsern, die installiert und bekanntgegeben werden. |
| Beziehungen zwischen Tabellen werden durch IdNummern oder anderSchlüssel dargestellt. Wenn z.B. Tabelle A in Spalte 5 eine Nummer hat, die innerhalb A eindeutig ist, können sich andere Tabellen auf diese Nummer beziehen, d.h. in Tabelle B kann z.B. Spalte 7 eine Nummer enthalten, die in A5 vorkommen muss. So werden auch Bestandteile zusammengehalten, die zu einem logischen Satz gehören, wenn dieser physisch auf mehrere Tabellen verteilt ist (s.o.). In einem View können genau die Elemente erscheinen, die für den Betrachter wichtig sind, d.h. keine IdNummern u.dgl., sondern Klartexte. | Beziehungen
zwischen Datensätzen werden durch IdNummern
oder andere Schlüssel dargestellt. Das Prinzip ist logisch gesehen
dasselbe wie in relationalen Datenbanken.
Für die Anzeige von Datensätzen und für die Indexierung gibt es außerdem eingebaute Mechanismen, die eine IdNummer durch einen Klartext ersetzen. Die scheinbare "Flachheit" der Dateien wird dadurch in ein potentiell komplexes Beziehungsgeflecht verwandelt, die Organisation der Dateien selbst und die Austausch- und Bearbeitungsvorgänge bleiben aber immer unkompliziert. |
| Für den
schnellen Zugriff und für geordnetes Browsing kann jede Spalte jeder
Tabelle indexiert werden. Es wird jeweils der gesamte Feldinhalt
indexiert. Eine Zerlegung des Feldinhalts z.B. für eine Stichwortindexierung
gibt es normalerweise nicht, dazu müssen zusätzliche Programme
geschrieben oder Extra-Tabellen angelegt werden, in jedem Fall ein recht
hoher Aufwand.
Ein Index kann in SQL nicht direkt angezeigt und
durchgeblättert werden, sondern nur über Views. Ein Index hat
eine andere Funktion als bei allegro! (s.o.)
Mehrere Spalten können einen gemeinsamen Index bilden.
(Wenn man mehrere Spalten für Namen oder Schlagwörter pro Satz
hat, wäre das sonst ein großes Problem.)
|
Für den
schnellen Zugriff und für geordnetes Browsing kann jedes Datenfeld
oder Teilfeld indexiert werden. Die Indexdatei einer Datenbank, eine B*-Baumstruktur,
kann bis zu 11 Register umfassen. Die Parametrierung
ermöglicht jede Art der Manipulation des Feldinhaltes sowie eine Mehrfachindexierung
eines Feldes und auch das Zerlegen in beliebiger Weise (Stichwortindex!).
Bei einem String-Index (Titel) können Nichtsortierwörter wie
Artikel am Anfang von der Ordnung ausgeschlossen werden.
In Registern kann man blättern, sogar trunkieren, und direkt Ergebnismengen bilden (mit Operatoren UND, ODER, NICHT). Registerausschnitte kann man kopieren. In Registern können Verweisungen erscheinen, die bei Anwahl zu einem anderen Registerabschnitt hinführen. Mehrere oder auch alle Felder können im selben Register indexiert werden. Jedes Feld oder Teilfeld kann in unterschiedlicher Form in mehreren Registern indexiert werden. Innerhalb eines Registers können durch beliebige Präfixe mehrere Abteilungen (logische Register) gebildet werden. Die Zahl 11 ist also keine Grenze. Register 11 kann aber nur mit bestimmten Privilegien benutzt werden (Datenschutz). Ein Nachteil ist, dass man Anzeige und Sortierung des Index nicht trennen kann, denn Sortierhilfen (Reduzierung auf Kleinschreibung, Einfügen von Leerschritten ...) bleiben so immer sichtbar (und evtl. für Benutzer verwirrend). Wirklich ausgleichen läßt sich dies in Client-Server-Anwendungen. |
| Zusammengesetzte Schlüssel (aus verschiedenen Spalten) sind meistens möglich (also nicht unbedingt plattformunabhängig). Wenn ja, ist zu fragen, was passiert, wenn z.B. das erste von zwei Feldern nicht besetzt ist. D.h. die Frage ist, ob es Möglichkeiten der Ausnahmebehandlung gibt. | Beliebige zusammengesetzte Schlüssel sind möglich. Die Parametrierung kann sinnvolle Behandlungen von Fällen vorsehen, wo einzelne Teile des Schlüssels im Datensatz nicht vorkommen. Ein allegro-Register ist, im Vergleich gesehen, eher so etwas wie ein "View", eine virtuelle Tabelle also. (Der Index wird in Realzeit aktualisiert) |
| Hierarchische Datensätze gibt es nicht, sie können nur als Teilmengen von Tabellen dargestellt werden. D.h. sie werden nicht durch Relationen zwischen mehreren Tabellen, sondern durch Relation einer Tabelle zu sich selbst dargestellt. Je nach Architektur sind verschiedene Strategien zur Lösung der satzübergreifenden Suche (sog. Schiller-Räuber-Problem) realisierbar. | Es gibt mehrstufige hierarchische Sätze, aber auch eine Abbildung von Hierarchien durch Satzverknüpfungen (heute die bevorzugte Methode). Dafür kann auch eine satzübergreifende Suche mittels Parametrierung eingerichtet werden. |
|
Zugriffsfragen |
|
| Auch ohne Index kann (mit Hilfe des Befehls SELECT von SQL) auf alles zugegriffen werden. Kleinere Datenbanken (unter 10.000 Sätze, nur wenige sind größer, auf's Ganze gesehen) werden oft ohne Index betrieben! Bei größeren Datenbanken dauert dies jedoch für den Normalbetrieb zu lange, besonders bei geordneter Anzeige und bei den beliebten "Joins" (Verbindung von Tabellen über gemeinsame Attribute). | Ohne Index kann mittels Volltextsuche zugegriffen werden. Die Datenbankgröße ist hier ebenfalls kritisch. Ca. 30 Minuten für 1 Mio Datensätze sind realistisch. Es wird praktisch keine Datenbank ohne Index betrieben, auch sehr kleine nicht, denn der Index ist integraler Teil des Konzepts. Die Indexzugriffe sind auch bei mehr als 1 Mio Sätzen noch sehr schnell. "Join"-Funktionen werden logisch gesehen über den Index bzw. über Satzverknüpfungen realisiert. |
| Fast jede Art von Abfrage und Auswertung kann mit Hilfe des SQL-Befehls SELECT programmiert werden, bis hin zur Ordnung und Gruppierung von Ergebnismengen. | Zugegriffen
wird i.d.R. über die Register, mit logischen
Kombinationen und Restriktionen können Ergebnismengen eingeschränkt
werden. Erstellung komplexer Listen mit spezifischer Ordnung und Gruppierung
oder Auswertung erfordert Kenntnisse der Parametrierung (Exportsprache).
Die Windows-Programme erleichtern die Listenerstellung sehr stark durch die neue "View-Technik". |
| Typische
Anfragen an eine relationale Datenbank:
"Bitte alle Angaben zu XYZ!" (Wobei XYZ typischerweise relativ kurz ist, etwa ein Name oder eine Bezeichnung, und seine genaue Schreibweise meistens bekannt.) "Wieviel Umsatz machten die Außendienstler im letzten Quartal?" "Welche Produkte waren im Vorjahr die Renner?" "Bei welchen Lieferanten kaufen wir am meisten?" "Welche Rechnungen des Vormonats sind noch offen? Was ist deren Summe?" Daraus wird klar, dass der Umgang mit Zahlen äußerst wichtig ist. Mit der Sprache SQL kann man solche Anfragen formulieren und Antworten in der gewünschten Form erhalten (geeigneter Datenbankentwurf vorausgesetzt). In Bibliotheken sind Fragen solchen Typs z.B. in den Geschäftsgängen Ausleihe und Erwerbung interessant, kaum im Katalogwesen. |
Typische Anfragen
an eine allegro-Datenbank:
"Bitte alle Angaben zu XYZ!" (Wobei XYZ oft ziemlich lang ist und seine genaue Schreibweise häufig nicht bekannt.) "Ist eine deutsche Ausgabe von 'The agony and the ecstasy' vorhanden?" (Wobei oft unbekannt ist, wie der deutsche Titel lautet (hier 'Michelangelo').) "Welche Werke von Tschaikowsky sind da?" (Und man erwartet eine vollständige und nach Werktiteln geordnete Liste, obwohl es über 30 Schreibweisen des Namens gibt und auch die Werktitel immer wieder anders geschrieben werden.) "Was gibt's zum Thema 'Drogenmissbrauch'?" (Egal, ob dieses Wort im Titel vorkommt oder z.B. 'Rauschgiftsucht' etc., auch englische Titel sind erwünscht, auch Arbeiten über Alkoholismus - oder solche eben gerade nicht.) Diese Fragen machen deutlich, dass man Register zum Browsing braucht und auch solche Dinge wie Einheitstitel und Normdaten für Namen und Schlagwörter. |
|
Datenaustausch |
|
| Die Ausgabe
von Daten in der jeweils benötigten Form ist Sache der Anwendungsprogrammierung.
SQL selber hat dazu nur geringe Mittel, es liefert nicht viel mehr als
Tabellenzeilen mit einem Trennzeichen zwischen den Feldern, ein sog. "Dumpfile".
Sehr erleichtert wird das Erstellen von Listen aber durch Reportgeneratoren. Flexible, leicht erstellbare Reports sind der wichtigste Zweck vieler RDBMS-Lösungen. Sie bilden eine wichtige Komponente von "Management-Informationssystemen". Datensätze im MAB-Format auszugeben ist dagegen eine ganz andersartige Aufgabe. |
Es existiert eine Exportsprache (eine eigens entwickelte Programmiersprache), mit der man Daten in fast beliebiger Aufbereitung ausgeben kann (z.B. auch in MAB oder MARC oder in der Form eines Dumpfiles, wie ein RDBMS es einlesen kann). Aus Gründen der Effizienz (z.B. hohe Geschwindigkeit beim Indexieren) ist die Sprache sehr kompakt und daher nicht leicht zu erlernen. Zwar kann man vielseitige Module schaffen, und es gibt solche für verschiedene Typen von Listen, aber so etwas wie einen universellen Reportgenerator gibt es noch nicht. Reports sind in den meisten allegro-Anwendungen eher Nebenprodukte. Oft reichen die Register oder die Kurzlisten, wenn sie geschickt gestaltet sind. |
| Die Umwandlung von Fremddaten ist gleichfalls durch Anwendungsprogramme zu lösen, SQL kann nur eine fertig vorbereitete Struktur verarbeiten (Felder mit Trennzeichen, Dumpfiles also). Oft wird die Umwandlung mit eigenen Perl-Programmen erledigt. | Es existiert
eine Datenmanipulationssprache, (sog. "Importsprache")
mit der man Fremddaten fast beliebiger Struktur in die eigene Struktur
umwandeln kann, bevor man sie mit dem DOS-Programm UPDATE oder dem Windows-Programm
a99
in die Datenbank einmischt. Auch Dumpfiles kann man leicht importieren,
denn sie haben eine immer gleiche Anzahl von Trennzeichen, das reicht als
Struktur aus.
Das Vorbereiten der Daten kann aber auch mit Perl o.ä. geschehen. |
| Programmierung | |
| SQL kann in andere Programmiersprachen (z.B. auch Perl) eingebettet werden, insbes. für Web-Anwendungen. | Neben den autonomen ("monolithischen") Zugriffsprogrammen (DOS, UNIX, Windows) gibt es für alle Plattformen den avanti-Server, dessen Abfragesprache in andere Sprachen (z.B. Perl, für Web-Anwendungen) eingebettet werden kann. |
| Ein RDBMS muß immer in eine Anwendungsumgebung (geschrieben z.B. in C, Visual Basic oder einer anderen geeigneten Sprache) eingebunden werden. Es hat keine für Anwendungen unmittelbar geeignete Benutzungsoberfläche. Es gibt jedoch mächtige Entwicklungssysteme, mit denen maßgeschneiderte (meistens maskenorientierte) Anwendungen ohne viel Programmierung interaktiv erstellt werden können. Die Übertragbarkeit auf ein anderes RDBMS ist dann aber wieder in Frage gestellt, auch die Optimalität für große Datenmengen ist nicht unbedingt gegeben. Wenn es aber um ad-hoc-Schnellschüsse für begrenzte Zwecke geht, hat man dafür hervorragende Werkzeuge. | allegro
enthält
alle Mittel, eine Anwendung komplett zu gestalten, bis hin zu einer mehrsprachigen
Oberfläche. Im Prinzip muss man also keine Programmiersprache können.
Zur normalen Benutzung einer Datenbank (Katalogisieren, OPAC) braucht man
nichts zu programmieren. Einbindung in Perl oder andere Sprachen
(z.B. auch Delphi) ist aber gleichfalls möglich, etwa für Web-Anwendungen.
Die wichtigsten Mittel sind die Exportsprache zur Gestaltung aller Anzeigen
und Ausgaben sowie die FLEX-Makrosprache zur Programmierung von Abläufen
(Windows).
Das Sortiment der allegro-eigenen Sprachen für Export, Import, Konfigurierung, Formulare und FLEXe ist allerdings auch nicht gerade sehr leicht zu erlernen. Es gibt Hilfen für den schnellen Aufbau einfacher Anwendungen, doch jenseits davon braucht man längere Einarbeitung. |
| Ein RDBMS arbeitet bei Mehrplatzbetrieb in der Regel als Client/Server-System. Anwendungsprogramme "unterhalten" sich also mit dem Server und greifen nicht selber direkt auf die Datenbank zu. Besonders für Web-Anwendungen ist die Client/Server-Architektur geradezu zwingend. | Es gibt sowohl monolithische Programme (unter DOS, Windows, UNIX), die selbständig lesend und schreibend (mehrplatzfähig) auf die Datenbank zugreifen, als auch einen Datenbankserver (avanti), für den man beliebige Client-Programme schreiben kann, auch für's Web. In lokalen Netzen wird fast nur mit den monolithischen Programmen gearbeitet (weil am schnellsten, und man muss keinen Server betreiben). Auch das Einmischen von neuen Daten kann im laufenden Betrieb durch monolithische Programme geschehen. |
| Mit sogenannten
ODBC-Schnittstellen,
oder auch den Perl-DBM-Modulen wird versucht, Anwendungen eine "generische"
relationale Datenbank vorzuspiegeln. Beispiel ist, dass mit und für
Microsoft Access (kein Client/Server) entwickelte Anwendungen dann ohne
Änderung auch mit dem Microsoft SQL-Server funktionieren.
Auch bibliothekarische Software unterstützt stellenweise mehrere relationale Datenbanken: "Bibliotheca Win" etwa das Centura RDBMS (vormals Gupta) als Low-Cost-Variante oder Oracle als High-Cost-Alternative. In der Windows-Welt gibt es über das COM-Konzept (Component Object Model) die Möglichkeit, dass andere Programme mit einem unsichtbaren Microsoft Access (z.B. lizenzierte Runtime-Version) oder einer anderen Datenbanksoftware über SQL-Befehle Datenbanken verwalten. |
Client/Server-Anwendungen können über TCP/IP den avanti-Datenbankserver in dessen Sprache ansteuern oder aber per sog. FLEX ein auf derselben Maschine laufendes Windows-allegro (a99). Dies ist eine Fernsteuerungsmethode vergleichbar mit der Fernsteuerung von Anwendungen über Visual Basic, hier aber mit einer allegro-eigenen Sprache. Diese Methodik für Windows-Anwendungen ist noch sehr neu und breitet sich zur Zeit erst unter Experten aus. Es wurden damit bereits Erwerbungs- und Ausleihfunktionen realisiert, aber auch eine neue Web-Schnittstelle ("RuckZuck"). |
|
Plattformen |
|
| Etliche RDBMS haben Versionen für UNIX, Linux und Windows. Aktuelle Versionen für DOS gibt es wohl nicht mehr, zumindest nicht für SQL-Systeme. (dBase ist zwar relational, hat aber kein echtes SQL und ist nur beschränkt mehrplatzfähig.) Ob zwischen den Plattformen stukturelle oder funktionale Unterschiede bestehen, ob Datenbanken unmittelbar kopiert werden können, muss man jeweils prüfen. | allegroexistiert für DOS, Windows (95/98 und NT), Linux und UNIX (SUN, HP, AIX, SINIX). Datenbanken können ohne Änderung zwischen den Plattformen kopiert oder auch via Samba zugleich von zwei Plattformen aus benutzt werden. Auch sehr alte PCs können immer noch als DOS-OPAC-Terminals dienen, während zugleich neuere Geräte unter Win'95/98/NT zugreifen. |
| Sicherheitsfragen | |
| Jede Schreib-Transaktion
muss auf ganz bestimmte Weise abgesichert sein, und zwar müssen die
sog. ACID-Bedingungen eingehalten werden:
Atomicity: Aktion wird ganz oder gar nicht ausgeführt Consistency: Zustand nach der Trans. muss wieder "integer" sein Isolation: das Ergebnis muss so sein, als liefe zugleich kein anderer Prozess. Dazu müssen alle Vorgänge "serialisierbar" sein (d.h. nicht echt parallel). Durability: Ergebnis muss hinterher sofort dauerhaft in der Datenbank stehen (nicht zuerst nur in einem Cache o.dgl.) |
Die ACID-Bedingungen
werden durch geeignete Maßnahmen erreicht. Insbesondere gehört
dazu das Sperren auf Satzebene bzw. im Index bereichsweise und wo nötig
auch in anderen Dateien (Adressentabelle). Vor dem Speichern können
programmierte
Validierungen die Integrität prüfen.
Die Satzsperre ist nie eine Lesesperre, d.h. Sätze, an denen gearbeitet wird, können im OPAC oder von anderen Bearbeitern jederzeit gelesen werden. Bleibt eine Satzsperre etwa durch Absturz eines PC bestehen, kann sie leicht aufgehoben werden. Eine Hilfsfunktion kann solche Sätze finden. |
| Alle Transaktionen werden in einem "Logbuch" aufgezeichnet, das im Falle eines Zusammenbruchs oder Systemfehlers für "Rollback" und "Recovery" sorgen kann. | Alle Speichervorgänge
werden in der Reihenfolge des Ablaufs (serialisiert) in einer LOG-Datei
aufgezeichnet (die auf einer anderen Platte liegen kann). Diese kann auch
zur regelmäßigen Aktualisierung einer Schattendatenbank dienen,
aber primär wird sie gebraucht, um aus einer Sicherungskopie der Datenbank
wieder den Zustand unmittelbar vor einem Zusammenbruch zu rekonstruieren.
Sichern muss man im Prinzip nur die Nutzdaten, alle anderen Dateien (Index, Kurztiteldatei etc.) sind daraus rekonstruierbar. Völliger Neuaufbau kann z.B. bei 1 Mio. Datensätzen in unter 8 Stunden ablaufen. |
| Leistungsbedarf | |
| Generell brauchen große, komplizierte Datenbanken große, schnelle Maschinen mit viel Arbeitsspeicher, um hohe Leistung zu erzielen. SQL-Systeme können z.B. bei Massenänderungen in einzelnen Tabellenspalten sehr schnell sein, denn oft wird dabei die gesamte Tabelle in den Arbeitsspeicher geladen. | allegro-Datenbanken mit Millionen Sätzen laufen immer noch mit guter Leistung auf Novell- oder NT-Servern und fordern weder für Client noch Fileserver extrem viel Arbeitsspeicher. Die Anforderungen an die Rechenleistung sind ebenfalls eher gering. Das Updating größerer Mengen von Sätzen ist aber zeitkritisch, weil jeder Satz zu seiner Bearbeitung mehrere Zugriffe erfordert. Da kommen schnell mal 1 oder 2 Sekunden pro Satz zusammen. |
| Der Speicherbedarf je Datensatz ist nicht bei jedem System gleich, er hängt vor allem davon ab, ob Tabellenspalten zur maximalen Länge mit Leerzeichen aufgefüllt werden oder nicht, und vom Bedarf der Indexdateien. Selbst wenn aber bis zu 5K je Satz gebraucht werden, wird das bei heutigen Plattenpreisen nicht mehr als Problem empfunden. Und im Vergleich zu Volltexten, das ist klar, brauchen Katalogdaten in jedem Fall sehr wenig Platz. | Typische Katalogdatensätze
brauchen im Schnitt unter 1000 Byte, einschließlich der Indexdatei
und der sonstigen Zusatzdateien. In den Sätzen gibt es keine Leerräume,
und der Index wird mit einer Komprimierungstechnik klein gehalten.
Von Vorteil ist dies, wenn eine Datenbank auf CD-ROM veröffentlicht werden soll (Maximum 640 MB). Es gibt Beispiele mit über 2 Mio. Datensätzen auf einer CD. |
Wer bis hierher gelesen hat, kann die Fragen des ersten Satzes leicht beantworten: "Keins" bzw. "Nein". Die zugrunde liegenden Vorstellungen, was denn eine Datenbank für Eigenschaften haben und was sie leisten soll, unterscheiden sich einfach zu stark. Manche Typen von SQL-Abfragen wird man mit Hilfe der FLEX-Technik und der Parametrierung nachbilden können, nicht jedoch die gesamte Bandbreite der SQL-Funktionen. Schließlich ist SQL ausdrücklich für RDBMS geschaffen worden, allegro aber hat aus guten Gründen ein anderes Konzept. Die Erwartung, beide könnten weitgehend kompatibel gemacht werden, ist also schlichtweg unrealistisch. (Umgekehrt könnte man mit SQL auch nicht alles nachbilden, was man mit allegro machen kann, z.B. das Blättern in Registern.)
Es wird aus dieser Übersicht hinreichend ersichtlich, dass beide Datenbankkonzepte ihre Stärken und Schwächen haben und welche das sind. Hätte eines der beiden keine Schwächen, würde es entweder allegro nicht geben, oder aber die UB Braunschweig wäre inzwischen die reichste Bibliothek der Welt.
Aber Scherz beiseite: durchaus denkbar sind hybride Anwendungen, die sich der Vorteile beider Systeme bedienen. Warum nicht z.B. Katalogisierung und OPAC mit allegro, Erwerbung und Ausleihe mit einem RDBMS. Beide können über ihre Schnittstellen sowohl die andere Datenbank befragen als auch ihr Auskünfte geben! Denkanstöße in dieser Richtung kann der hier vorliegende Vergleich möglicherweise geben.
Vergleichweise noch weitaus seltener anzutreffen und in der Standardisierung noch nicht so weit fortgeschritten sind Objektorientierte Datenbanksysteme. Zu deren Grundkonzept hat allegro eine viel größere Ähnlichkeit als zum RDBMS-Konzept. Mehr zu diesem Thema steht unter http://www.allegro-c.de/allegro/a-o.htm .
CockPit-Funktionen in a99
1. Wichtige Dateien
Die wichtigen Dateien, die zu einer Datenbank gehören, kann man jetzt alle direkt aus a99 heraus zur Bearbeitung abrufen.
Start: Im Schreibfeld gibt man ein: h adm
Dann erscheint im Anzeigefeld dieses Menü:
|
Angaben zur Datenbank |
||
| INI-Datei
(Vorgaben zu dieser Sitzung) Konfiguration (Feldstruktur der Datenbank) Anzeigeparameter (mit sofortiger Aktualisierung) Druckparameter (mit sofortiger Aktualisierung) Indexparameter (sofortige Aktualisierung möglich) Formulardatei (zur Unterstützung des Editierens) Hilfedatei (Hilfe zur Datenbank) |
Satz sperren/freigeben (für Schreibzugriffe) Schreibsperre/-freigabe
Totalsperre
HILFE..HILFE..HILFE
|
Empfehlung:
Wer mit den hier auftretenden Begriffen wenig anzufangen weiß, sollte sich das Kapitel 0 des Systemhandbuchs zu Gemüte führen. Die Begriffe werden dort erklärt. Wenn man z.B. auf das Wort "Konfiguration" doppelklickt, wird die Konfigurationsdatei der Datenbank zum Bearbeiten vorgelegt. Dazu öffnet sich ein DOS-Fenster und darin erscheint die Datei. Nur keine Panik! Anhang D des Hand-buchs erklärt auf nur einer Seite, wie die Bearbeitung mit dem sog. X-Editor geht. |
Wenn man auf HILFE..HILFE..HILFE doppelklickt, kommt eine ausführlich kommentierte Fassung desselben Menüs (Datei admin.rtf). Es erübrigt sich deshalb, hier alle Punkte zu erläutern. Wer das CockPit kennt, kann sich denken, was gemeint ist, ansonsten gibt die Online-Hilfe genügend Hinweise.
Interessant für Allegrologen: die bisher nur bei den Anzeigeparametern bekannte Testmethode "Merseburger Testschleife" gilt nun auch für die Indexparameter und für die Konfiguration, sowie für die INI-Datei: Direkt nach der Änderung kann diese sofort aktiviert und die Wirkung geprüft werden.
Als Editor zur Bearbeitung der Dateien wird standardmäßig der X-Editor benutzt, mit dem Befehl Editor=... kann man in der INI-Datei einen anderen einstellen. Notepad, Wordpad oder andere Windows-spezifische Editoren empfehlen sich nicht, weil diese alle mit ANSI-Codes arbeiten, für die Parameter und CFG ist aber ASCII notwendig. Schrecken Sie vor dem X-Editor nicht zurück! Es braucht wirklich nur 2 Minuten, die notwendigen Dinge zu erlernen, eine einzige Seite im Handbuch reicht dafür aus (Anhang D). Das ist das geringste Problem, viel schwieriger ist die Exportsprache, die man für Index-, Druck- und Anzeigeparameter kennen muss. Für die Konfiguration ist auf Handbuch-Anhang A zu verweisen.
Für die Hilfedatei wird der Editor Wordpad aufgerufen, da es sich um eine RTF-Datei handelt. Die Datei heißt bei der Demo-Datenbank CATGER.RTF (bzw. CATENG.RTF, wenn die Sprache Englisch eingestellt ist). Für Ihre eigene Datenbank müssten Sie sich eine solche Datei mit Hilfe des Wordpad-Editors erst noch anlegen. Sie können dabei von einer Kopie der Datei CATGER.RTF ausgehen.
Auf der rechten Seite gibt es drei Funktionen zum Sperren und Freigeben:
Satz sperren/freigeben
Tip: Die "Organisier"-Funktionen des konventionellen
CockPit
sind auch verfügbar: geben Sie ein h org
Eine Übersicht der Online-Dokumentation erhält
man, wenn man im Schreibfeld h doku
eingibt:
Im Anzeigefeld erscheint dann diese Übersicht:
|
|
|
| Allgemeines | allegro - Was ist das?
Elemente des Programms Grundbegriffe
|
| Daten | Datenschema
Formulare - Dateneingabe Fremddaten-Import - Export, Listen - Views Tastenfunktionen - Phrasen Sonderzeichen-Eingabe - Zeichensatz
(ANSI-Codes)
|
| Systemverwaltung | Management-Funktionen
Installationshinweise - Liste der Dateien Initialisierung (INI-Datei) FLEX-Sprache Hilfekonzept Systemhandbuch Hintergründe
|
Die unterstrichenen Bezeichnungen stehen jeweils für eine RTF-Datei, die mit Doppelklick aufzurufen ist. In manchen Fällen, so z.B. im Fall "Systemhandbuch", kommt eine Übersicht, die wiederum unterstrichene Bezeichnungen enthält. Wie bei einem Web-Browser kann man den "Zurück"-Button links oben dazu benutzen, zu vorher aufgerufenen Texten zurückzuschalten.
Ist wieder ein Datensatz in der Anzeige, kann man die zuletzt besichtigte Hilfeseite über das Menü "Anzeige" wieder zurückholen.
Tip: Machen Sie Kopien der Datei doku.rtf oder adm.rtf, wenn Sie ähnliche Menüs mit eigenen RTF-Dateien und/oder FLEXen anlegen wollen. Die Bearbeitung solcher Dateien ist am bequemsten mit dem Programm WordPad, das zu Windows gehört. (Die Datei help.rtf, die hinter "Hilfekonzept" steckt, erläutert alles Weitere.)
Installation der V20a
Die CD-ROM V20a enthält eine aktualisierte V20. Zur Installation gilt dieselbe Schlüsselzahl, die auf der Rechnung für die V20 mitgeteilt wurde. Fertigen Sie also mit Hilfe dieser Zahl zuerst die 3 Installationsdisketten an, dann legen Sie die erste davon ein, wenn eine Neuinstallation vorzunehmen ist, sonst die zweite. Im ersten Fall ist INSTALL.BAT von der Diskette zu starten, im zweiten Fall wählt man im CockPit den Menüpunkt "Routinen / Neue Version installieren / Update-Installation".
Wir empfehlen wie immer dringend, dass Sie Ihre vorhandene Installation aktualisieren. Änderungen an Datenbanken oder eigenen Parametern sind nicht notwendig. Sieht hinterher die Anzeige anders aus oder die Registereinträge, oder ist die Abfrage neuer Daten anders als vorher: reaktivieren Sie Ihre alten Parameter über den CockPit-Menüpunkt "X : EXTERN" unter "Routinen", danach die Funktion "0 - Eine alte Datei wieder aktivieren" und D-1.APR wählen für die Datenanzeige, CAT.API für die Indexparameter, $A.CFG für die Abfrageliste. Das ist alles. Nur keine Angst: es kann nichts kaputtgehen, Sie gewinnen im Gegenteil mehr Sicherheit.
Hinweis für die Windows-Programme: Benutzen Sie die Datei FILELIST.TXT als Checkliste.
E-Mail-Diskussionsliste [DIE Adresse für alle akuten Fragen und Probleme]
Man schließt sich den ca. 280 Lesern der allegro-Liste an, indem man an die Adresse maiser@buch.biblio.etc.tu-bs.de eine Botschaft mit nur einer Zeile sendet: subscribe allegro . Man wird dann sofort eingetragen und erhält eine Mitteilung mit weiteren Informationen, insbesondere, wie man sich wieder abmeldet. Es gibt auch ein Archiv der Liste.