for Unicode see: http://www.unicode.org/standard/WhatIsUnicode.html
Looking at a character in a display, what is the reality behind it?
Two things are necessary to know:
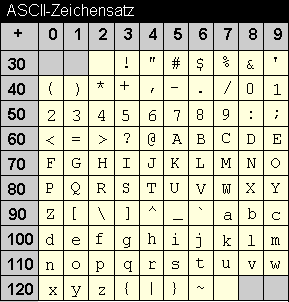
Only the lower 127 byte values are universally standardized across platforms. Here's the so-called ASCII table:
The German special characters (Umlaut letters and ß) are not part of this standard. A truly international character repertoire would consist of many more than just 256 different characters. Therefore, the traditional equation of 1 character = 1 byte had to be abandoned.
How was Unicode constructed?
First, a long list was compiled containing
all characters to be found in the many languages of the world that have alphabets
or other graphic representations. The list ran to no less than 95.221 characters
when Chinese and other ideographic systems were included.
This list was grouped into meaningful sections, the 127 ASCII characters
being the first one. Then, the whole list was numbered, leaving some space
at the end of sections. But there is still the requirement to code everything
into bytes. Most, if not all, characters on the list therefore have to be
represented by more than one byte.
To solve this, i.e. to actually code the Unicode numbers, several methods were invented:
2. Mixed
MethodS : Only 1 byte for the ASCII codes of 0 to 127, but more
than one for all others.
This approach comes in two variants:
2a. &#N;
codings (so-called "Entities"), N is the list number of the character:
for example, character number 128 is saved as €, 129 as  and so on.
Modern browsers understand that, when found in an HTML source, and will show
the corresponding character.
The German ä thus gets the encoding
ä, the Euro sign € will be € (=U+20AC)
- every special character beyond 127 thus gets represented by a sequence
of no less than 6 to 8 bytes. Programs dealing with this meathod have to
be on the lookout for the entity sequence&# : it announces
a special character if followed by digits and terminated by a semicolon.
numbers can also be given in hexadecimal, preceded by an x; the Euro will
then appear as € .
2b. UTF-8 : Another list is prepared,
assigning two or three numbers to every entry beyond 127; the first one must
be beyond 191 if it is a two-byte code, or beyond 224 for three-byte codes,
the second (and third) beyond 127 but below 192. The ä = 228 is assigned
the sequence of (195,164). There's a relatively simple algorithm for computing
the two numbers. It makes sure no confusion can occur when copying parts
of files because at every point one can determine whether the byte found
there is the beginning of a character code sequence or not.
Which Method is the best?
That depends on the data. If it is
predominantly normal letters, digits and punctuation, then Method 2b. If
one has mostly East Asian material, then Method 1.
Unicode from a library viewpoint
A brief presentation by Joan Aliprand
(Stanford) was published in 1999 for IFLA meeting in Bangkok. There's a German version
of it.
Variant 1 : Internal codes unmodified, additional characters as HTML4 entities
Variant 2 : Everything in UTF-8 (i.e., only codes below 128 unchanged)
Variant 1Export
Schon mit den bisherigen Mitteln (p/q-Befehle)
lassen sich sowohl "Entitäten" wie auch UTF-8-Codes erzeugen.
Empfehlung: die bereitgestellte
Tabelle d-utf8.apt in Anzeige- oder Ausgabeparameter einbinden.
Das einzige Problem ist das der Akzente.
Hierfür wurde ein Unterprogramm erstellt, das in gleicher Weise, nur umgekehrt,
beim Import eingesetzt werden kann: es setzt das diakritische Zeichen jeweils
hinter das nachfolgende Zeichen bzw. umgekehrt. Ausgeführt wird es innerhalb
der Exportparameter mit #da bzw. #dA vorwärts bzw. rückwärts., im FLEX: dow a bzw. dow A (Beispiel: edrec.php im RuckZuck-PHP-System)
Das wirkt auf den gesamten Arbeitsspeicher
+ Hintergrundspeicher (#u-Variablen)!
Die Akzentliste muss in einer der Export-Parameterdateien
hinterlegt sein, sie ist dann intern global. Der Standard sieht so aus (Liste
aller DOS-Codes der diakritischen OstWest-Zeichen):
pa=181 182 183 184 189 190 198 199 207 208 209 210 211 212 219 222 223 232
Empfehlung: Kopieren Sie diese
Zeile in Ihre Indexparameter, dann gilt sie überall da, wo es drauf ankommt.
Bei Verwendung in IMPORT.EXE: Einbau in die benutzten Exportparameter.
(In der Liste der DOS-Akzentcodes findet man die Bedeutung dieser
Zahlen.)
Import
Damit man damit keine Probleme hat, sind folgende Dinge nötig:
Die umzuwandelnden UTF-Codes müssen
in u-Befehlen stehen, ebenfalls in einer der verwendeten Export-Parameterdateien.
(Empfehlung für a99: Indexparamerterdatei, denn diese wird in jedem
Fall geladen.) Diese u-Zeilen, es können bis zu 800 Stück sein, sehen so
aus:
| u 195 161 160
u 226 130 172 221 u 195 129 065 181 u 195 163 097 232 |
LATIN SMALL LETTER
A WITH ACUTE á EURO SIGN € LATIN CAPITAL LETTER A WITH ACUTE Á LATIN SMALL LETTER A WITH TILDE ã |
u zzz yyy xxx bbb aaa Kommentar
zzz yyy xxx sind die dezimalen UTF-8-Codes des Zeichens.
Wenn zzz<224 ist, dann fehlt xxx, was bedeutet, dass es sich um einen
2-Byte-UTF-8-Code handelt.
Zum Ausrechnen dieser 3stelligen Zahlen
steht ein JavaScript-Progrämmchenbereit. Man
tippt nur die 2-Byte-Unicode-Hexzahl ein, z.B. 20ac, und
erhält die UTF-8-Codes in Dezimal (nur diese werden gebraucht) und als Zugabe
in Hex. Das Progrämmchen kann aber gleich einen ganzen Block von 256 Zeichen
als Codeliste ausgeben, die man sich dann kopieren kann [funktioniert nur
mit IE, nicht Netscape].
Achtung: Ab V23.2 kann man statt
der Dezimalzahlen direkt die UTF-8-Zeichen hinschreiben, für bbb und aaa die
DOS-Zeichen, jeweils ohne Blank dazwischen.
bbb ist der OstWest-DOS-Code, aaa wird nur angegeben, und muss dann einer der DOS-Akzentcodes sein (siehe oben im pa-Befehl), wenn auf allegro-Seite der akzentuierte Buchstabe als Einzelzeichen nicht existiert, wie z.B. Á und ã.
Die u-Befehle werden nur für die Umwandlung von Fremddaten benutzt, nicht für den Export. Also i.d.R. beim Einlesen einer ADT-Datei, die in UTF-8 codiert ist, bzw. beim Übergeben von HTML-Formulardaten an den avanti-Server, oder auch im DOS-Konvertierprogramm IMPORT.EXE.
Im FLEX setzt man vor die Befehle
zum Einlesen der Daten den Befehlset U1 , dahinter set U0. Achtung: Das Vertauschen von Akzenten
und Buchstaben erfolgt dabei automatisch im Anschluss an das Umwandeln der
Codes (beim FLEX-Befehl insert) .
Beispiel: siehe write.php im PHPAC-System.
Für das Programm IMPORT setzt man die u-Befehle in die dabei benutzten Exportparameter (!), dann passiert die Umwandlung ganz automatisch, und zwar jeweils beim Einordnen eines fertigen Datenfeldes in den entstehenden Datensatz. Außerdem gehört in die Exportparameter der Befehl #dA. Die Befehle in den Paragraphen der Importparameter "sehen" deshalb noch die nicht umgewandelten Daten!
Wir haben dank der Hilfe von Thomas Berger eine u-Liste von ca. 300 akzentuierten Buchstaben erstellt, die als Datei ucodes.txt mit V23 mitgeliefert wird. Berger hat auf seinem Server weitere empfehlenswerte Materialien und relevante Dokumentationen: weitere u-Codes findet man in mit Kommentar in einer Datei uc-ow.cpt. Oder man benutzt das besagte Progrämmchen.
Nicht berücksichtigt sind Kombinationen
von Buchstaben mit zwei Diakritika, deren es im Unicode durchaus etliche
gibt. Solche werden also in die Entitäts-Darstellung verwandelt.
Generell werden Zeichen, die in der
u-Liste nicht vorkommen, in die Entitätenform &#N; umgewandelt. Das Programm
errechnet den Wert N aus dem UTF-Code. Man muss also z.B. für die kyrillischen
oder griechischen Zeichen keine u-Zeilen bereitstellen, das muss man nur
für solche Zeichen, denen man eine Entsprechung in seinem eigenen Codesystem
zuordnen will (in der Regel also OstWest-Code).
Export
Wenn man "Entitäten" in den eigenen
Daten (innerhalb der Datenbank also) verwenden will, sollte man die "Stammdatei"
vs.alg zuerst einmischen. Damit diese Daten korrekt indexiert werden,
muss man die entsprechenden Abschnitte aus cat.api in die eigenen Indexparameter
übernehmen (darin Kommentar "V23").
In den betroffenen Exportparametern wäre
dann zu setzen:
i6=10 Ersetzungsreg. ist Nr. 10
dx=1 Codierungen ausführen (wichtig bei ANzeigeparametern)
p & 9 Zeichen & ist zuständig für VS-Ersetzungen
ib=59 ; ist das Endezeichen der Entitäten
In den Exportparametern wird man normalerweise#dV
setzen (zu empfehlen in Indexparametern), dann werden alle Ersetzungen zu
dem Zeitpunkt auf einmal ausgeführt, und nachfolgende Exportbefehle sehen
nur noch die ersetzten Zeichen!
Der entsprechende FLEX-Be fehl heißt
dow V . Dabei werden die VS-Ersetzungen genutzt, die in den Indexparametern
stehen. Dort muss also u.a. der Befehl p & 9 vorkommen.
Export mit dem Befehl "write ..."
( in a99 und avanti)
Der FLEX- bzw. avanti-Befehl write ...
wirkte bislang so, dass die Zeichenkette, die er produziert, unverändert in
die Ausgabedatei geschrieben wird. Daher konnte man mit "write" keine Umcodierung
vornehmen, das ging nur über die Exportfunktion "download", weil dabei eine
Parameterdatei zum Einsatz kommt. Deshalb wurde "write" so erweitert, dass
dabei eine automatische Umcodierung erfolgen kann. Man muss nur zwei Dinge
tun:
1. in die benutzten Exportparameter diesen Abschnitt einbauen:
zl=0 kein Zeilenumbruch
dx=1 damit Umcodierung ausgefuehrt wird
td-utf8 Tabelle d-utf8.apt laden
#-X Sprungmarke
#u1 die von write erzeugte Zeichenkette ausgeben
#+# Ende
2. Im FLEX vor dem "write"-Befehl
diese Befehle einbauen
dow wX Abschnitt #-X in den Exportparametern aktivieren
dow a Akzente verschieben
write ...
write ...
dow A Akzente zurück (nur nötig, wenn der Satz anschließend gespeichert
werden soll.
Kompromiss
Es gibt Zeichen, wie z.B. Á und ã, die in Unicode als Einzelzeichen existieren, in OstWest aber nicht. In einer allegro-Datenbank werden sie traditionell als ´A bzw. ~a eingegeben und gespeichert. Beim UTF-8-Export werden diese nicht zusammengefasst, sondern es werden zwei Zeichen daraus: Buchstabe+Akzent, also umgekehrt. Dies ist in der Unicode-Welt eine korrekte Alternativ-Darstellung, aber besser wäre natürlich der Export in der Form des korrekten Einzelzeichens. Wenn andererseits die Eingabe über ein Web-Formular erfolgt, können dort zwar die Einzelzeichen eingegeben werden, aber was in der Datenbank ankommt (Anwendung der u-Befehle!) , ist die Kombination Akzent+Buchstabe, nicht die "Entitäts-Darstellung" des kombinierten Zeichen. Wichtig ist das deswegen, weil damit ganz leicht die korrekte Indexierung in der Datenbank möglich ist: dabei wird einfach der Akzent weggelassen, aus Á und ã wird a. (Im Index würden Akzente die Sortierung stören, deshalb müssen sie wegfallen!) In einer Unicode-Datei kann ferner auch ein Buchstabe mit zwei nachfolgenden Diakritika vorkommen. Dies wird korrekt behandelt: in der allegro-Datei kommen beide vor dem Buchstaben an, das Akzentvertauschungs-Unterprogramm regelt das in beiden Richtungen.
Eingabe-Unterstützung für Verfahren 1
Die VS-Stammsätze dienen zugleich
dazu, Indexeinträge bereitzustellen, die man zum Suchen und Übernehmen der
"Entitäten" verwenden kann. Im Übernahme-Register steht dann z.B. unter u
diese Liste:
u a BREVE+ACUTE _ắ
u a BREVE+DOT BELOW _ặ
u a BREVE+GRAVE _ằ
u a BREVE+TILDE _ẵ
u a CARON _ǎ
u a CIRC+ACUTE _ấ
u a CIRC+DOT BELOW _ậ
u a CIRC+GRAVE _ầ
u a CIRC+TILDE _ẫ
u a DOT ABOVE _ȧ
u a DOT ABOVE+MACRON _ǡ
u a DOT BELOW _ạ
u a MACRON _ā
u a RING ABOVE+ACUTE _ǻ
u a TILDE _ã
u a TREMA+MACRON _ǟ
u ae ACUTE _ǽ
u ae MACRON _ǣ
u b DOT ABOVE _ḃ
u b DOT BELOW _ḅ
u kyr B _Б nur als Beispiel: kyrillischer Großbuchstabe БMan gibt z.B. "u a" ein, wenn man ein a mit irgendeinem Akzent sucht. Dann erscheint diese Liste. Balken auf die richtige Zeile setzen, den Button [Kopie] drücken (Alt+k) - die Sequenz wird in die Eingabe kopiert.
Man gibt z.B. "kyr a" ein, um zu dem Abschnitt der kyrillischen Kleinbuchstaben zu kommen.
In die Standard-Parameter cat.api sind die nötigen Zusätze eingebaut, kommentiert mit "V23", damit man sie leicht findet und in andere Indexparameter übernehmen kann.
Web-Schnittstelle (für beide Verfahren gültig)
Zum Eingeben in einem Web-Formular, z.B.
bei RuckZuck-PHP, kann man das MS-Programm CHARMAP verwenden. Das sieht z.B.
so aus:

Dies ist die XP-Version! Unter NT
und '98 gibt es erheblich weniger Möglichkeiten.